What is Data Science?
In a growing data-centric world, it is of fundamental importance to get familiar with the field of study that forms around data and provides effective insights to many disciplines.




Data Science is an interdisciplinary field of study that applies modern tools and techniques to various types of data to derive meaningful insights. Data might differ in nature and collection, its analysis can change depending on the purpose, the insights obtained can be applied to different disciplines.
To give an idea of how important Data Science has become in the last years, consider that, according to IDC, the “Global Datasphere” in 2018, including all data created, captured, or replicated, was 18 zettabytes. Each zettabyte corresponds to around one trillion (10^12) gigabytes or one sextillion (10^21) bytes. In short, 18 zettabytes are a massive amount of data.
Furthermore, it is evident from the graph below how the “Global Datasphere” is expected to grow exponentially in the following years, reaching 175 ZB in 2025.
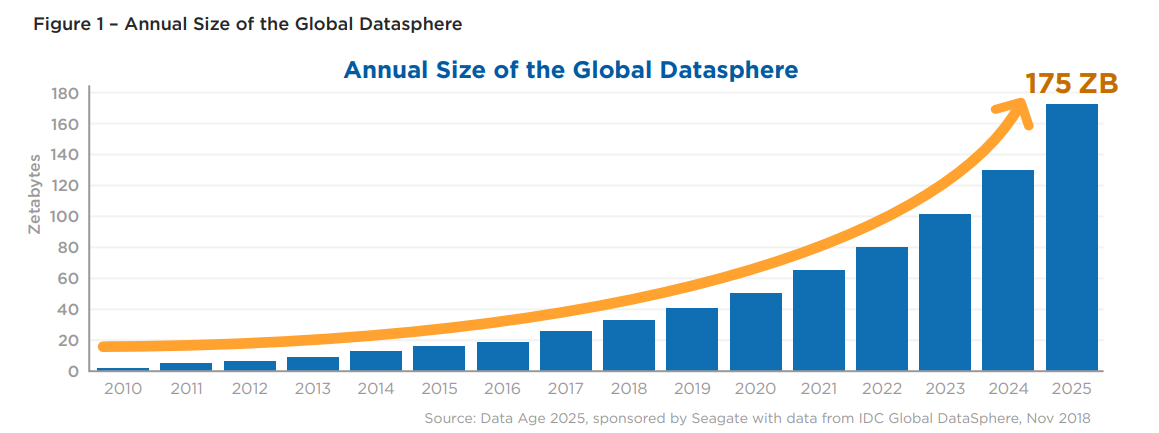
With this information in mind, it is now interesting to uncover the main processes related to the collection of data and to its analysis. Additionally, we will explore the most relevant applications of Data Science nowadays.
Data Collection
Data can be found in the form of numerical values or descriptions regarding a subject. Numerical values are known as quantitative data, meaning the researcher can measure the data statistically. Examples of quantitative data include the height or weight of an individual. On the contrary, qualitative data is non-numerical and can be arranged based on attributes or properties. For instance, it could describe a person’s hair color or the shape of her face.
In today’s digital era, the supply of data has become one of the highest priorities for companies. Hence, modern data scientists are invested in finding new and effective methods for collecting data.
Data collection is a systematic approach to accumulating information from different sources, allowing researchers to answer questions and assess outcomes. Depending on the nature of the investigation, data collection can be split into two categories: Primary Data Collection and Secondary Data Collection.
Primary Data Collection is the procedure of gathering data from interviews, experiments, or surveys. Using this approach, a scientist must generate her data through empirical inquiry, examining its source directly.
Primary Data Collection allows researchers to personally guarantee the quality and truthfulness of the information collected. Indeed, before choosing a data collection source, a scientist must first identify the scope of the investigation and the target population of the analysis. Another key element of Primary Data Collection is the possibility to filter data to meet specific research demands.
Nevertheless, Primary Data Collection also shows downsides: it is often very time-consuming, expensive, and prone to bias.
An example of Primary Data Collection is the one concerning Market Research. Firms constantly conduct deep research to determine the potential of a new service or a product. Furthermore, Market Research can be useful to discover the target market or receive feedback from consumers. A company that wants to gather information for the mentioned purposes is likely going to collect the relative data directly from the public and the consumers.
Secondary Data Analysis makes use of pre-collected data, meaning that the information used has been previously gathered by a researcher. Secondary Data is accessible through various sources such as websites, books, newspapers.
An important advantage related to the use of Secondary Data is that it allows researchers to save time and money by skipping the collection part (which instead needs to be carried out for primary data).
One of the most popular tools used to collect secondary data are bots: software able to automatically browse through enormous amounts of information online and return the required material. Bots are a fundamental resource for the biggest tech companies like Facebook and Google, which continuously pull data from forums and social media.
Data Cleaning
Once collected, the raw data isn’t really meaningful in its form, especially for big data. To extract valuable insights, companies must resort to data analytics. However, before being able to carry out any significant analysis, the data must be cleaned, or the output will be messy and unusable (this is encapsulated rather elegantly by a famous phrase in data analytics: “Garbage in, garbage out.”). There are many issues to address, including:
Removal of duplicate data
Dimensionality (are there too many variables?)
Structural errors (these could be caused by data type inconsistencies, input errors, etc.)
Missing values
Outliers (data that is abnormally large/small)
Amount of observations (is there too much/little data? Will this lead to over/underfitting?)
Standardization of data (ensure that all data follows a specific format, units of measure, etc.)
It would not be wise to apply algorithms to data that, for instance, contains missing values. How should the missing data be dealt with? Completely removing variables or observations containing missing values is a potential solution, but this leads to a loss of information, which is typically undesirable. An alternative, more appealing solution is to “predict” the missing value. This can be achieved in numerous ways, ranging from simpler methods (like using its mean value across the other observations) to more ingenious ones (like the “nearest neighbor” method: this consists in identifying the complete record most similar to the problematic one and using it to infer the missing value). In the end, the decision of how to deal with missing data will largely depend on the particular context and the desired outcome of the analysis.
Data cleaning can be a tedious task. Missing data is only one of the many issues to address when preparing data for analysis. Depending on the problem, different solutions have to be evaluated to determine the best approach.
Data Analysis
Once data is clean, it is finally ready to be analyzed. It is here that one can truly appreciate the power of Data Science and understand why companies value data so highly. There are four different levels of analysis that may be carried out:
Descriptive (What happened?): This analysis offers some descriptive statistics about the collected data but does not attempt to determine relationships in the dataset.
Diagnostic (Why did it happen?): There is an attempt to establish causal relationships within the dataset to explain the reason behind certain observations.
Predictive (What will happen in the future?): By exploiting the causal relationships identified, accurate predictions can be made regarding future events.
Prescriptive (What is the optimal course of action? This is also called data mining): This is just an extension of predictive analytics, which specifically addresses a company’s requests.
While descriptive and diagnostic analysis can be insightful, the last two types hold the most value for a business.
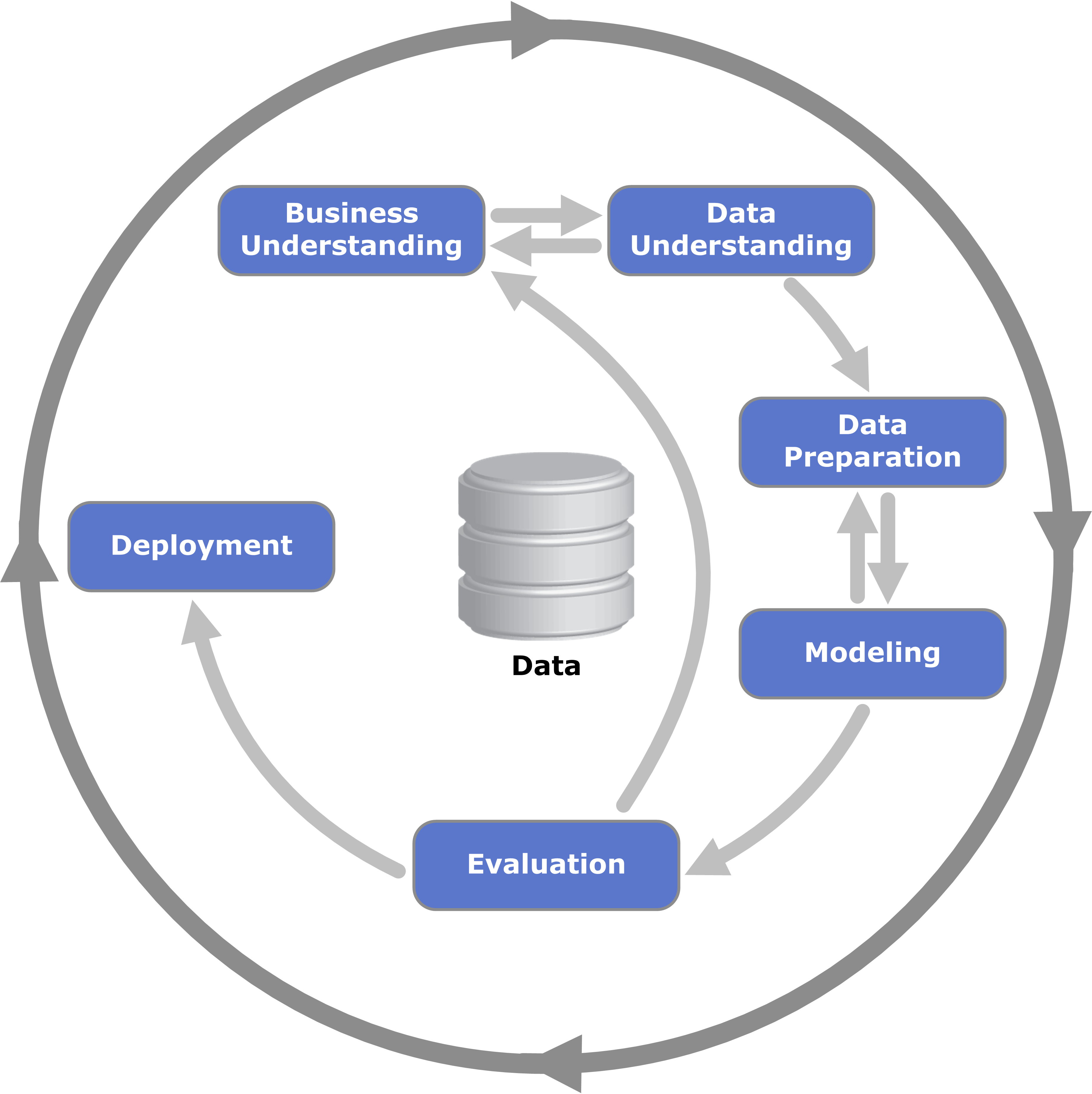
Typically, the goal of data analysis for a company is to build accurate predictive models based on past data so that future trends may be anticipated, allowing companies to make informed, optimal decisions. The following diagram represents the “Cross Industry Standard Process for Data Mining” (or CRISP-DM for short) which, as the name aptly suggests, is an open methodology used to create predictive models.

CRISP-DM diagram - Kenneth Jensen, CC BY-SA 3.0, via Wikimedia Commons
{kind=link}
{kind=link}
We have arrived at the modeling stage. To be deployed effectively, models must be optimized through an iterative process of evaluation and re-modeling called “training”, which makes use of machine learning techniques. The training that a model undergoes varies depending on the type of analysis. Models are divided into three families based on their learning style:
Supervised Training: a specific target variable for which to create a predictive model must be identified. Two of the most common problems companies tackle through supervised learning models are regression (quantitative prediction of the target variable based on other observations) and classification (categorization of the object/event of interest).
To evaluate a model, the cleaned data is typically split into a training set and a testing set. The former is the dataset algorithms use to construct the model, while the latter is used to evaluate its accuracy. Indeed, the newly created model predicts the target variables based on the testing dataset. The predicted values can then be compared with the real values to make assessments through statistical methods.
The name of this type of model is fitting, as someone will have to supervise this process and correct the relative inaccuracies.
Unsupervised Training: no target variable is given. The model is tasked with finding patterns in datasets autonomously. The main problem unsupervised models are applied to is clustering, which splits the given data into groups based on shared similarities. Typically, an unsupervised model will operate independently. However, it can also be “steered” in the right direction by being fed with some labeled training data (this is known as semi-supervised training).
Reinforcement learning: this is the newest training class, and it is applied to highly dynamic tasks. It follows a trial & error approach based on three principles: state - action - reward. These models autonomously determine the optimal actions to be taken by being continuously provided with positive or negative feedback relative to specific activities (reinforcement). Essentially, they must learn by themselves.
Depending on the particular task that a company wants to tackle, several algorithms could seem appropriate for the job. The following diagram (made by a Python library dedicated to machine learning, Sci-kit-Learn) provides an idea of how such algorithms are selected:
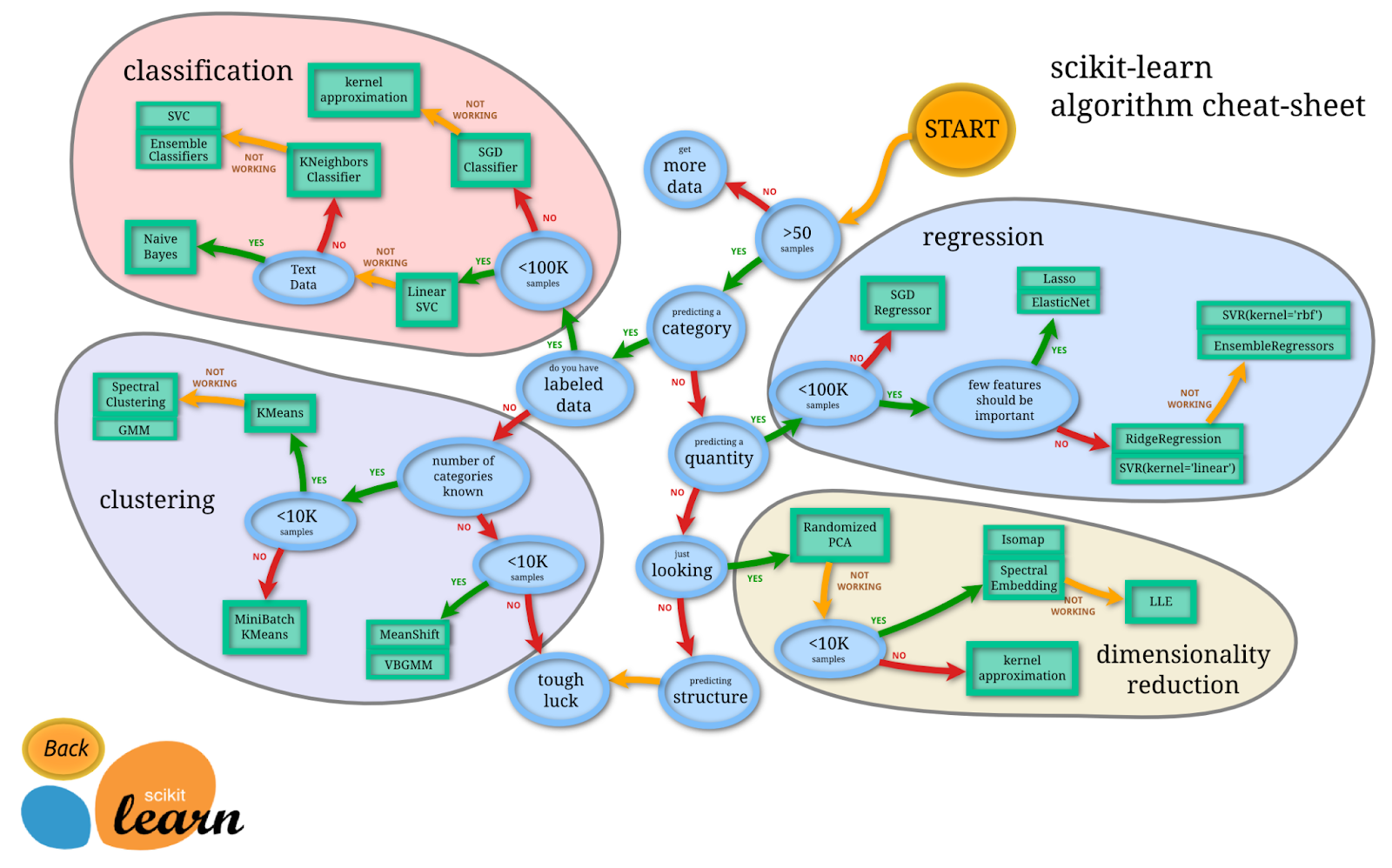
Diagram of estimators, via Sci-Kit Learn
{kind=link}
It is impossible to know a priori which algorithm is optimal. Therefore, multiple models are created and their performance is subsequently evaluated and compared (the particular evaluation method will vary depending on the type of model considered). Once the best model is identified and ready to be used by the company, it still needs to be monitored to ensure its quality does not falter with time or new data.
Applications of Data Science
Having described the main procedures related to the collection and the analysis of data, it is now interesting to examine the main applications of Data Science.
1. Manufacturing and Logistics
Despite recent bottlenecks in the World Economy, Data Science has been a cornerstone of the manufacturing and supply chain industry over the past few years.
Among their applications, Data Science algorithms are key for optimizing costs and efficiency, fostering the "just-in-time" (JIT) philosophy of Western Economies. Stemming from Japan, JIT manufacturing has been particularly efficient in meeting effective demand without surpluses or shortages.
Furthermore, the Internet of Things (IoT) can enhance this process: data-collecting manufacturing machines can now analyze continuous streams of data while monitoring, cross-communicating, and making use of reinforcement learning.
Finally, when a product is ready to ship, the Travelling Salesman Problem (TSM) demonstrates how difficult it could be to computationally optimize a day of work.
For example, UPS has decided to incorporate machine learning tools to crack challenging logistics puzzles such as how packages should be rerouted around bad weather or service bottlenecks. The tool allows data scientists to simulate a variety of workarounds and pick the best ones. According to internal estimates, the platform has saved UPS $100 to $200 million in 2020.
2. Healthcare
Do not sweat! We have not reached the point where algorithms write medical reports. Yet, where the weary eye of the doctor may lack reliability, medical image analysis comes in.
Indeed, the most promising applications of Data Science in the field can read through evolving images of tumors and detect early signs if they were to appear. This technique applies machine learning methods, namely wavelet analysis for solid texture classification and support vector machines (SVM), to enhance image processing.
Despite the complexity of modeling real-world scenarios, Data Science is increasingly used to prevent outbreaks and flu transmission. Pfizer and Johnson & Johnson gave Data Science techniques the pivotal role of predicting COVID-19 hotspots. Their research identified potential samples within the population according to age, gender, or ethnic group that tailored the COVID-19 vaccine to the most effective outcomes despite the tight time constraints.
Last but not least, the vast amount of data collected in medical sciences is being put to practical use in genome sequencing and drug development. In brief, the goal is to understand how DNA structure relates to people’s health and find biological connections between genetics, diseases, and drug response. Big data technologies like MapReduce have significantly reduced the processing time for genome sequencing and biologically relevant computer simulation to assert inference between drug use and consequences.
3. Finance
In finance, the most reputed use of Data Science and Machine Learning techniques dates back to the concept of algorithmic trading, which brought the concept of "quant" to the industry. Ever since the renowned hedge fund Renaissance Technologies, founded by the former mathematician Jim Simons, popularized the concept of "High-frequency Trading" (HTF) and the use of pattern recognition in stock charts, the statistical trading revolution began.
Nevertheless, financial data offers an incredibly low signal-to-noise ratio (which implies having much irrelevant information), and most strategies tend to remain property of the retailer's sight.
In the banking sector, the R&D effort is prominent. The use of Data Science in banking can be traced back to 1987 when the Security Pacific National Bank in the US set up a Fraud Prevention Taskforce to counter the unauthorized use of debit cards. Nowadays, with the higher computing power of modern-day GPUs, the vast amount of consumer data helps banks understand if a customer should be under scrutiny, either by cross-checking with tax forms or by analyzing his/her loan data in the past.
4. Internet Search
Internet Search Engines are doing their best to optimize their efficiency despite the exponential expansion of the World Wide Web.
For example, Google processes more than 20 petabytes of data every day. Its Data Science team collects consumer data (from users who accept cookies) to set a map of their preferences. This way, every user can experience a tailored form of the internet, albeit this has raised concerns over "parallel" search engines that could create political backlashes and foster biases.
Overall, one thing is clear: Data Science has revolutionized marketing so much that targeted advertising has become the industry standard thanks to its above-average retention rate.
5. Self-driving Cars
The industry of self-driving cars has arguably been one of the most media-invested industries, both for technological breakthroughs and competition. New players such as Tesla and Uber are racing against the established R&D teams of Apple and Google (Waymo).
Self-driving cars represent an extreme challenge of complexity by requiring robotics, mechatronics, and Data Science — most notably, pattern recognition — to work at the same time to foresee human behavior in the surroundings.
The sheer amount of data to be collected represents a paramount challenge for returning sensible outputs. The reason stems from a subtle fact: although Data Science can make the best use of the data available, it has two fragile issues. Firstly, it has to face the tradeoff of accuracy vs speed, posing challenges to emergency situations. Secondly, while Data Science algorithms can unlock key patterns and leverage their power against similar-but-unforeseen data, they cannot face “black swans”, i.e. events that cannot be rationally or statistically predicted.
The last pitfalls mentioned are just a few of the cutting-edge research challenges being tackled now. As more and more industries eagerly await to tap into the Data Science field, a future data revolution cross-fertilizing many jobs is expected. As the discipline evolves, BSDS will be here to inform, challenge, and analyze the world around Data Science.
Bibliography:
Cover picture by Gerd Altmann from Pixabay.
The Digitization of the World from Edge to Core
Data collection:
https://www.questionpro.com/blog/data-collection/
https://dimewiki.worldbank.org/Primary_Data_Collection
https://www.formpl.us/blog/secondary-data
Data Analysis:
https://serokell.io/blog/how-to-choose-ml-technique
SKIENA, STEVEN S. Data Science Design Manual. SPRINGER INTERNATIONAL PU, 2018.
Applications of Data Science:
https://blog.routific.com/travelling-salesman-problem
https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.28.3242&rep=rep1&type=pdf
https://www.jnj.com/innovation/how-johnson-johnson-uses-data-science-to-fight-covid-19-pandemic
https://www.jpmorgan.com/technology/applied-ai-and-ml
https://www.datacenterknowledge.com/archives/2008/01/09/google-processing-20-petabytes-a-day
finance image by Gerd Altmann from Pixabay.
Subscribe to BSDS blog
By BSDS · Launched 9 days ago
Data Science
Subscribe
Like Comment Share
Ready for more?
Subscribe
© 2021 BSDS. See privacy, terms, and information collection notice